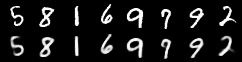Training a Variational Auto-Encoder¶
This guide will give a quick guide on training a variational auto-encoder (VAE) in torchbearer. We will use the VAE example from the pytorch examples here:
Defining the Model¶
We shall first copy the VAE example model.
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, 400)
self.fc21 = nn.Linear(400, 20)
self.fc22 = nn.Linear(400, 20)
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
def reparameterize(self, mu, logvar):
if self.training:
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
return eps.mul(std).add_(mu)
else:
return mu
def decode(self, z):
h3 = F.relu(self.fc3(z))
return F.sigmoid(self.fc4(h3))
def forward(self, x):
mu, logvar = self.encode(x.view(-1, 784))
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
Defining the Data¶
We get the MNIST dataset from torchvision and transform them to torch tensors.
BATCH_SIZE = 128
normalize = transforms.Compose([transforms.ToTensor()])
# Define standard classification mnist dataset
basetrainset = torchvision.datasets.MNIST('./data/mnist', train=True, download=True, transform=normalize)
basetestset = torchvision.datasets.MNIST('./data/mnist', train=False, download=True, transform=normalize)
The output label from this dataset is the classification label, since we are doing a auto-encoding problem, we wish the label to be the original image. To fix this we create a wrapper class which replaces the classification label with the image.
class AutoEncoderMNIST(Dataset):
def __init__(self, mnist_dataset):
super().__init__()
self.mnist_dataset = mnist_dataset
def __getitem__(self, index):
character, label = self.mnist_dataset.__getitem__(index)
return character, character
def __len__(self):
return len(self.mnist_dataset)
We then wrap the original datasets and create training and testing data generators in the standard pytorch way.
# Wrap base classification mnist dataset to return the image as the target
trainset = AutoEncoderMNIST(basetrainset)
testset = AutoEncoderMNIST(basetestset)
traingen = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=8)
testgen = torch.utils.data.DataLoader(testset, batch_size=BATCH_SIZE, shuffle=True, num_workers=8)
Defining the Loss¶
Now we have the model and data, we will need a loss function to optimize. VAEs typically take the sum of a reconstruction loss and a KL-divergence loss to form the final loss value. There are two ways this can be done in torchbearer - one is very similar to the PyTorch example method and the other utilises the torchbearer state.
PyTorch method¶
The loss function from the PyTorch example is:
def loss_function(recon_x, x, mu, logvar):
BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), size_average=False)
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
This requires the packing of the reconstruction, mean and log-variance into the model output and unpacking it for the loss function to use.
def forward(self, x):
mu, logvar = self.encode(x.view(-1, 784))
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
def bce_plus_kld_loss(y_pred, y_true):
recon_x, mu, logvar = y_pred
x = y_true
return loss_function(recon_x, x, mu, logvar)
Using Torchbearer State¶
Instead of having to pack and unpack the mean and variance in the forward pass, in torchbearer there is a persistent state dictionary which can be used to conveniently hold such intermediate tensors.
By default the model forward pass does not have access to the state dictionary, but setting the pass_state flag to true in the fit_generator call gives the model access to state on forward.
torchbearer_model.fit_generator(traingen, epochs=10, validation_generator=testgen, callbacks=[AddKLDLoss(), SaveReconstruction()], pass_state=True)
We can then modify the model forward pass to store the mean and log-variance under suitable keys.
def forward(self, x, state):
mu, logvar = self.encode(x.view(-1, 784))
z = self.reparameterize(mu, logvar)
state['mu'] = mu
state['logvar'] = logvar
return self.decode(z)
The loss can then be separated into a standard reconstruction loss and a separate KL-divergence loss using intermediate tensor values.
def bce_loss(y_pred, y_true):
BCE = F.binary_cross_entropy(y_pred, y_true.view(-1, 784), size_average=False)
return BCE
Since loss functions cannot access state, we utilise a simple callback to complete the loss calculation.
class AddKLDLoss(Callback):
def on_criterion(self, state):
super().on_criterion(state)
KLD = self.KLD_Loss(state['mu'], state['logvar'])
state[torchbearer.LOSS] = state[torchbearer.LOSS] + KLD
def KLD_Loss(self, mu, logvar):
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return KLD
Visualising Results¶
For auto-encoding problems it is often useful to visualise the reconstructions. We can do this in torchbearer by using another simple callback. We stack the first 8 images from the first validation batch and pass them to torchvisions save_image function which saves out visualisations.
class SaveReconstruction(Callback):
def __init__(self, num_images=8, folder='results/'):
super().__init__()
self.num_images = num_images
self.folder = folder
def on_step_validation(self, state):
super().on_step_validation(state)
if state[torchbearer.BATCH] == 0:
data = state[torchbearer.X]
recon_batch = state[torchbearer.Y_PRED]
comparison = torch.cat([data[:self.num_images],
recon_batch.view(128, 1, 28, 28)[:self.num_images]])
save_image(comparison.cpu(),
str(self.folder) + 'reconstruction_' + str(state[torchbearer.EPOCH]) + '.png', nrow=self.num_images)
Training the Model¶
We train the model by creating a torchmodel and a torchbearermodel and calling fit_generator.
model = VAE()
optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=0.001)
loss = bce_loss
from torchbearer import Model
The visualised results after ten epochs then look like this: